
缓冲区溢出攻击
缓冲区溢出攻击
前言
哎,提前进组压力真的很大,奉劝大家还是不要提前进组吧。学长叫你干的活你又不懂,md又push你,老师又要叫你做PPT汇报,感觉已经成了一种恶性循环。
程序的内存布局
为了深入理解缓冲区溢出攻击的工作原理,需要了解进程中的内存是如何分布的。对于一个典型的C语言程序,它的内存由5个段组成,每一个段都有不同的用途。下图展示了这5个段在进程中的分布。
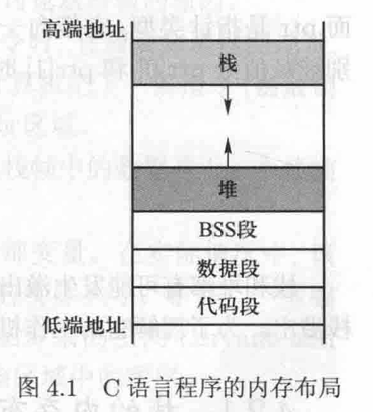
- 代码段(text segment):存放程序的可执行代码。这一内存块通常是只读的。
- 数据段(data segment):存放由程序员初始化的静态/全局变量。例如,static int a=3 定义的变量a将会存储在数据段中。
- BSS段(BSS segment):存放未初始化的静态/全局变量。操作系统将会用0填充这个段,因此所有未初始化的变量都会被初始化为0。例如,static int b 所定义的静态变量b将保存在BSS段中,并且被初始化为0。
- 堆(heap):用于动态内存分配。这一内存区由malloc()、calloc()、realloc()、free()等函数管理。
- 栈(stack):用于存放函数内定义的局部变量,或者和函数调用有关的数据,如返回地址和参数等。后续将详细介绍这个部分。
为了理解不同内存段是如何被程序使用的,来看下面的代码。
int x = 100; |
在上面的程序中,变量x是程序中初始化的全局变量,因此这个变量会被分配到数据段中。变量y是一个未初始化的静态变量,因此y被分配至BSS段。变量a和b时局部变量,因此它们保存在程序得栈中。变量ptr也是一个局部变量,因此它也被分配至栈中保存。然而ptr是指针类型,它指向一个由malloc()函数动态分配的内存块,因此,当数值5和6分别被赋值给ptr[0]和ptr[1]时,它们被保存在堆中。
栈与函数调用
栈和堆都有可能发生溢出,但是对于这两种溢出的利用方法却有很大差别。本章着重谈论栈溢出。为了理解它的工作机制,需要深入理解栈的工作原理以及在栈中存储的信息。
栈的内存布局
栈中存储了函数调用时使用的数据。一个程序的执行过程是由一些列的函数调用构成的。当一个函数被调用时,需要在栈中为该函数分配一些空间以执行该函数。例如,以下func()函数的示例代码中包含两个整型参数(a和b)及两个整型局部变量(x和y)。
void func(int a,int b) |
当func()函数被调用时,操作系统将在栈顶为其分配一块内存空间,这块内存空间称为栈帧。栈帧布局如下,一个栈帧拥有以下4个关键区域。
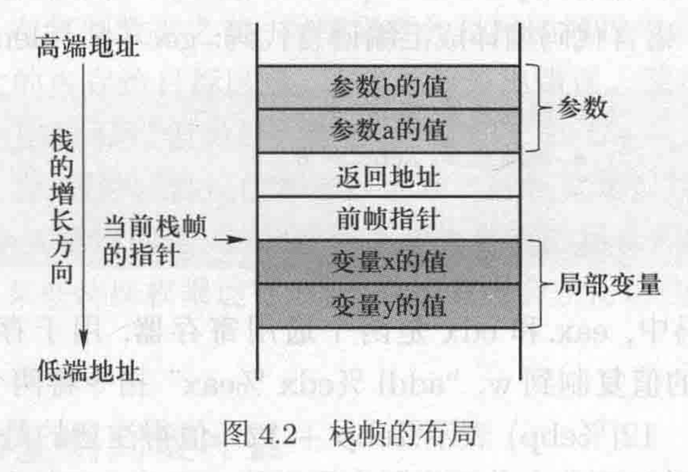
- 参数:这个区域用于保存传递给函数的参数。在示例中,func()函数拥有两个整型参数。当这个函数被调用时,例如func(5,8),参数的值将会被压入栈中。值得注意的是,参数是以相反的顺序压入栈中。介绍完帧指针后将讨论这样做的原因。
- 返回地址:当函数结束并执行返回指令时,它需要知道返回地址,也就是需要将返回地址存在某个地方。在调用一个函数之前,计算机把下一条指令(函数调用指令的下一条指令)的地址压入栈顶,这就是栈帧中的返回地址区域。
- 前帧指针:下一个被程序压入栈帧中的数据是上一个栈帧的指针。后面会详细解释前帧指针。
- 局部变量:该区域用于存放函数的局部变量。在实际情况中,该区域的布局取决于编译器,例如局部变量的存储顺序、区域的实际大小,等等。一些编译器可能随机设置局部变量的存储顺序,或者为这个区域分配多余的空间。程序员不应假定该区域的大小以及变量在该区域中的顺序。
帧指针
在func()函数中,需要访问参数和局部变量。访问参数和局部变量的唯一方法是通过它们的内存地址。然而,这些地址在编译时并不能确定,因为编译器无法预测栈的运行时状态,也就无法得到栈帧的位置。为了解决这个问题,CPU引入了一个专门的寄存器,叫做帧指针。这个寄存器指向栈帧中的一个固定地址,因此参数和局部变量的地址可以通过这个寄存器加上一个偏移值计算得到。偏移值在编译时确定,而帧指针的值却决于运行时栈帧被分配至栈的哪个位置。
下面通过一个例子来观察帧指针的使用情况。之前的示例代码表明,函数将执行x=a+b。CPU需要获取a和b的值,把它们相加得到的结果存在x中,因此CPU需要知道这三个变量的地址。如图4.2所示,在x86架构中,帧指针寄存器(ebp)总是指向前一个帧指针保存的地址。对于32位体系架构而言,返回地址以及帧指针各占据4个字节,因此参数a和b的实际地址分别是ebp+8和ebp+12。所以,x=a+b的汇编代码如下:(可以使用”gcc -S”选项把C语言代码编译成汇编代码:gcc -S\
movl 12(%ebp), %eax ; b的地址是%ebp+12 |
在上面的汇编代码中,eax和edx是两个通用寄存器,用于存放临时的计算结果。”movl u w”指令将u的值复制到w,”addl %edx %eax”指令将两个寄存器内的值相加并把结果保存在%eax中。12(%ebp)表示%ebp+12。值得注意的是,变量x实际上被分配到比帧指针低8字节的地址而非之前示意图中现实的4字节。正如之前提到的,局部变量的实际内存布局是取决于编译器的。由汇编代码中的-8(%ebp)能看出,x存放%ebp-8的地址中。因此,通过帧指针以及编译阶段确定的偏移值,就能够找到所有变量的地址。
现在可以解释为什么a和b是以逆序压入栈中。实际上,从偏移角度来看,顺序并不是反的。由于栈是从高端地址向地段地址增长的,如果先压入参数a,a的偏移值将会高于b,这反倒会在阅读汇编语言代码时感觉顺序反了。例如:a的地址是%ebp+12。b的地址是%ebp+8,就会感觉反了。
前帧指针和函数调用链。通常会在一个函数内调用另一个函数。当进入被调用函数前,程序会在栈顶为被调用函数分配一个栈帧。当程序从被调用函数返回时,该栈帧占据的内存空间将会被释放。如下图所示,main()函数调用了foo()函数,而foo()函数又调用了bar()函数。在这个过程中,三个函数调用的栈帧皆分布于栈中。
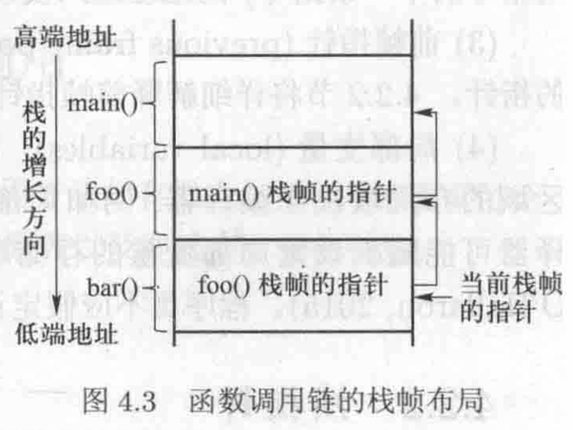
CPU中仅存在一个帧指针寄存器,它总是指向当前函数的栈帧。当进入bar()函数之前,帧指针指向foo()函数的栈帧,当程序跳转到bar()函数时,帧指针将指向bar()函数的栈帧。如果不记得进入进入bar()函数之前帧指针指向的地址,那么一旦从bar()函数返回,将无从知晓foo()函数的栈帧在什么位置。为了解决这个问题,在进入被调用函数之前,调用者的帧指针的值(称为前栈指针)将会被存储到被调用函数栈帧中的一个固定位置(在返回地址的下面)。当被调用函数返回时,这个位置中存放的值会被用于设置调用者的帧指针寄存器,从而使帧指针重新指向被调用者的栈帧。







